Un sistema di impaginazione per riviste scientifiche basato su pandoc
30 Mar 2018Nel mio lavoro, un servizio universitario per la pubblicazione di riviste scientifiche ad accesso aperto, non abbiamo mai fornito alcuna soluzione per l’impaginazione e la composizione tipografica degli articoli. Le riviste, prive di supporto in questo lavoro non semplice, hanno esplorato varie strade, perlopiù legate alle abitudini degli autori (e quindi anche degli editor) nei propri ambiti disciplinari. Le due principali opzioni sono l’uso di LaTeX, per quelle poche e fortunate discipline nelle quali gli autori sono abituati all’uso di questa tecnologia di composizione tipografica, e l’affidamento a professionisti esterni – normalmente utenti di InDesign. Queste due opzioni sono evidentemente limitate a poche discipline, o alla (rara!) disponibilità di fondi. Per questo motivo la maggioranza delle nostre redazioni si è dovuta sempre affidare all’impaginazione tramite Microsoft Word o altri programmi di videoscrittura.
Queste soluzioni hanno svariati limiti: il principale è che l’unico formato di pubblicazione è in pratica il PDF, standard di fatto per gli articoli scientifici, che imita il passato cartaceo della comunicazione scientifica. D’altra parte per considerarlo adeguato ai tempi, un formato di pubblicazione dovrebbe garantire almeno una impaginazione non fissa ma adattabile al dispositivo di fruizione, e una certa espressività semantica.1 In queste soluzioni la preparazione di una versione HTML degli articoli è – nei casi migliori – non semplice né lineare, e spesso è del tutto impossibile ottenere una qualità adeguata e la necessaria coerenza dei vari impaginati. Ci sono inoltre altri limiti – talvolta molto seri – alla qualità dei PDF, con problemi frequenti quali: indirizzi web non funzionanti, mancanza di un indice e dei metadati, pessima resa nella composizione tipografica (in particolare se si utilizza un semplice programma di videoscrittura) e veri e propri drammi dovuti a episodiche conversioni dei testi in formato immagine. Per le redazioni che lavorano con programmi di videoscrittura, il lavoro ha significato anche notevoli perdite di tempo con la formattazione, la microgestione delle spaziature e degli stili, e una inquietante quantità di errori: c’era gran bisogno di qualcosa di più affidabile ed efficace.
Nel 2017 ho infine iniziato a esplorare tra le soluzioni che consentissero la preparazione di articoli in più formati. Quanto segue è un flusso di lavoro ancora sperimentale, che intende rappresentare una buona soluzione per riviste accademiche che impiegano OJS come piattaforma di pubblicazione e per la gestione delle proposte di articolo. È basata su pandoc, un software fantastico, e si affida all’accoppiata del markdown (per il corpo del testo) and YAML (per i metadati e le impostazioni), che rappresentano una alternativa più amichevole e leggibile all’XML.
Vedi markdown-workflow su Github
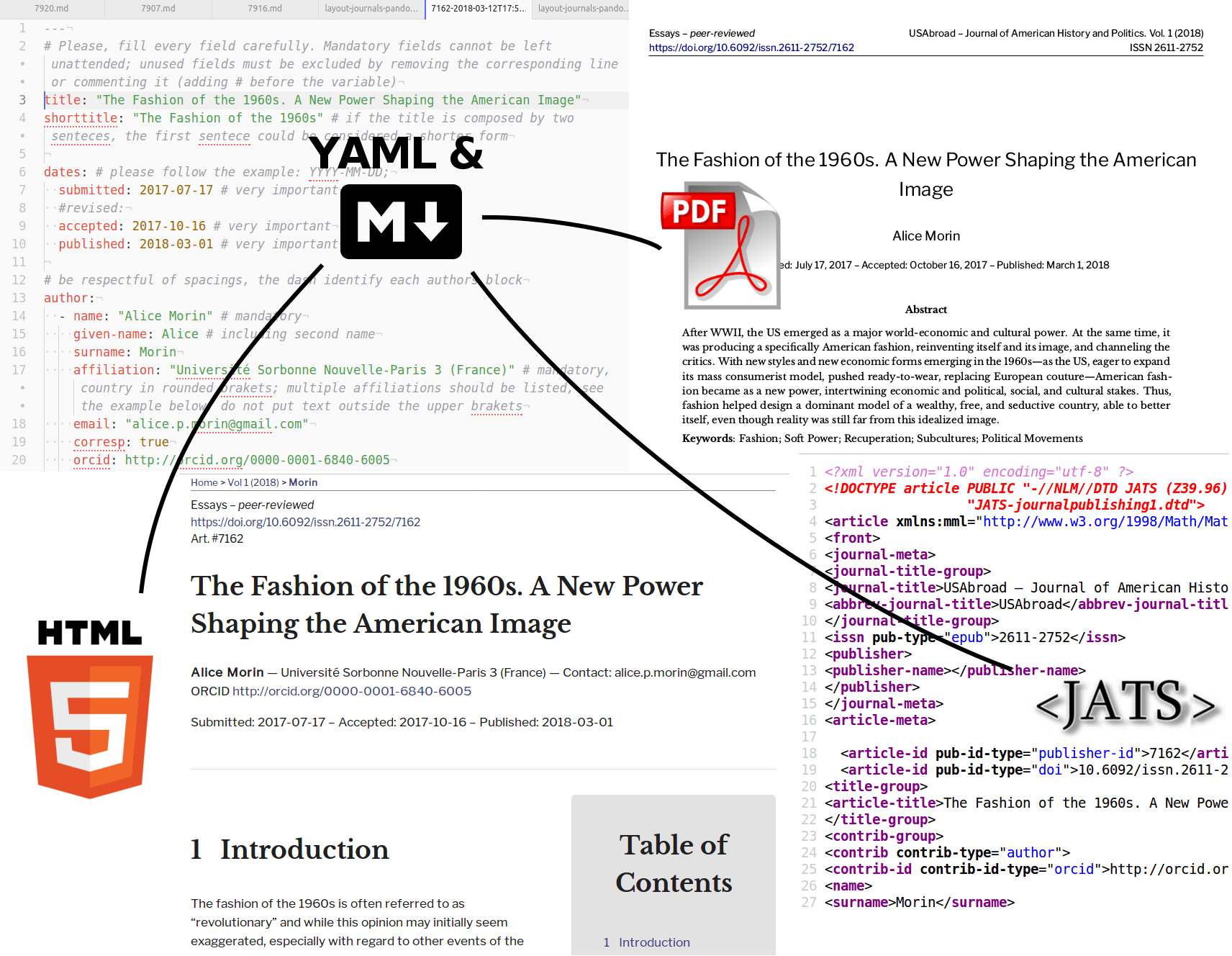
Two formats to rule them all
Perché un’altra soluzione?
NB: Scrivendo questi appunti sono incappato in un paper, recentemente pubblicato, che affronta lo stesso problema individuando sostanzialmente la stessa soluzione, anche se in maniera più evoluta:
Albert Krewinkel e Robert Winkler, «Formatting Open Science: agilely creating multiple document formats for academic manuscripts with Pandoc Scholar», PeerJ Computer Science 3 (8 maggio 2017): e112; https://doi.org/10.7717/peerj-cs.112.
Esistono varie soluzioni per realizzare articoli scientifici in HTML in maniera efficace, come le varie versioni di Scholarly HTML e Scholarly Markdown.2 Probabilmente tra queste la soluzione più completa e potente è Research Articles in Simplified HTML (RASH) Framework, che fornisce una annotazione semantica completa per metadati, testo dell’articolo e riferimenti bibliografici.
Purtroppo però tutti questi progetti sono rivolti agli autori, piuttosto che alle redazioni. A mio parere in questo modo però non riescono a rappresentare una soluzione sostenibile per piccole redazioni. Infatti le riviste scientifiche più piccole non possono richiedere agli autori di adeguarsi a requisiti stringenti e complessi per la proposta degli articoli. La predominante esigenza di una bassa complessità nella gestione dei testi e dei metadati degli articoli (rispetto agli editor), e nella realizzazione di script e modelli (rispetto a me e le mie capacità) è la ragione principale per la scelta di pandoc, del markdown e dello YAML come della strada più praticabile ed efficace.
Pandoc, markdown e YAML
Ho già scritto un paio di post sulla potenza di pandoc e la semplicità di markdown e YAML. In breve, pandoc è un convertitore di testi universale e potente, in grado di gestire la conversione di testi in una grande quantità di formati.
Markdown e YAML sono due linguaggi leggeri e semplici3 che possono funzionare da formato di scambio per i testi formattati (markdown) e i dati strutturati (YAML). In confronto all’XML sono di gran lunga più lineari, semplici da leggere e da scrivere; inoltre la loro ampia adozione li rende una buona soluzione per i flussi di lavoro, per le conversioni tra formati e per futuri riutilizzi dei testi.
L’idea principale è quella di ottenere, per ciascun manoscritto, una copia in markdown che consenta di gestire la fase di “layout” (o impaginazione), utilizzando pandoc per convertire (#1) i manoscritti partendo dai formati DOCX o ODT,4 estraendo nel mentre quanta più formattazione e semantica possibile dai testi – come ad esempio le intestazioni delle sezioni in cui è diviso un articolo, le citazioni lunghe, le note a piè pagina o i link esterni. Gli articoli convertiti in markdown perderebbero inoltre tutta la complessità dei formati Word, derivante dagli stili, formattazione personalizzata (come evidenziazioni etc), commenti, revisioni etc.
Successivamente gli articoli convertiti in markdown possono essere lavorati dalle redazioni per la formattazione finale, sistemando la sintassi di markdown dove fosse necessario: markdown consentirà loro di focalizzarsi sul significato del testo, piuttosto che sull’aspetto; tutta la parte grafica sarà gestita separatamente e con metodi più robusti. Un secondo compito per la redazione consiste nell’inserimento dei metadati di ciascun articolo tramite YAML: questa sintassi può essere usata all’interno dello stesso file in markdown, avendo in questo modo un unico file per il testo e i metadati. Inserire i metadati in maniera strutturata, piuttosto che inseriti come semplice testo, è importante non solo in quanto consente una gestione più coerente ed efficace dell’aspetto finale, ma anche perché consente una grande riusabilità dei dati e la conversione tra formati, come un XML.
Quanto un articolo in markdown + YAML è pronto, pandoc rientra in gioco per convertirlo (#2) in vari formati per la pubblicazione, posto che siano presenti dei modelli adatti a utilizzare i vari metadati e impostazioni elencate in formato YAML.
Il flusso di lavoro
Chiedere alle redazioni – di area umanistica e di scienze sociali – di lavorare con markdown, YAML e un editor di testi semplici è stata una scommessa. E son felice di dire che per il momento ho vinto la scommessa.
Per ridurre la mole di complessità e per trarre vantaggio dalla serializzazione, il flusso di lavoro avviene all’interno di una cartella condivisa ed è governato da script. La cartella condivisa consente un carico di lavoro distribuito alla redazione, evitando loro le parti più tecniche: l’uso della riga di comando e l’installazione di una distribuzione LaTeX. Attualmente questa parte è realizzata centralmente da me, tramite una cartella condivisa con ciascuna rivista e lanciando manualmente gli script di conversione quando necessario.
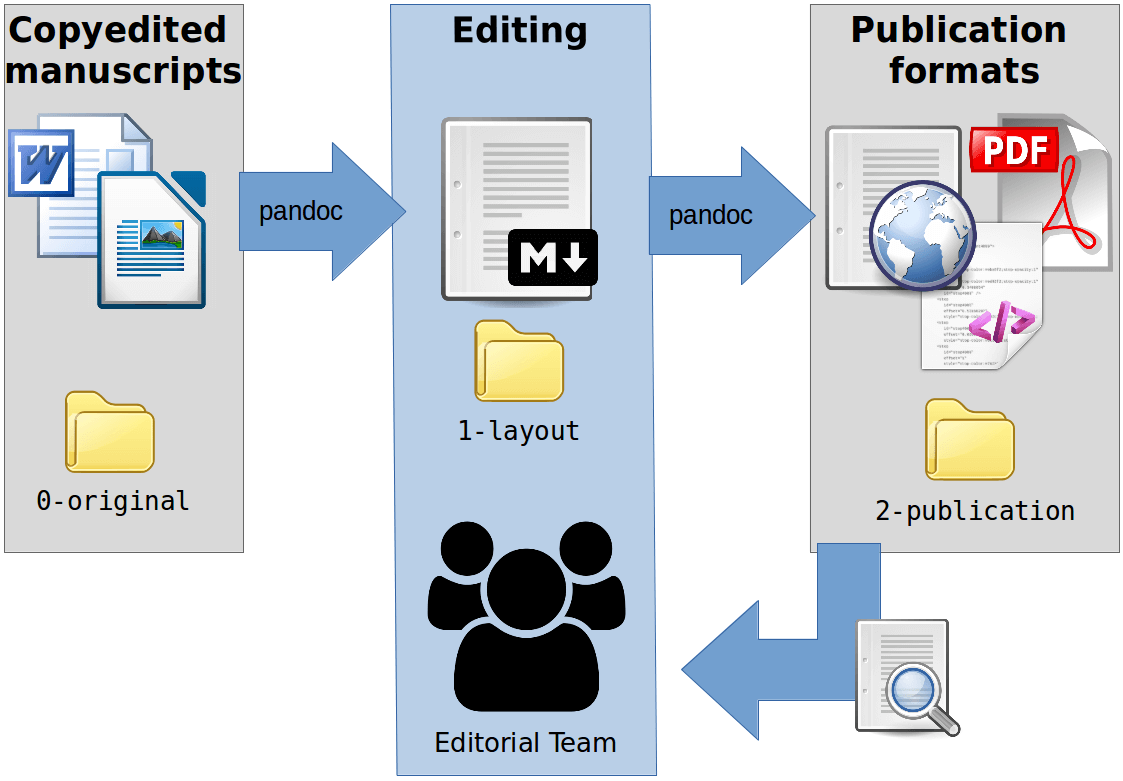
Una brutta rappresentazione del flusso di lavoro
Come visto nella sezione precedente, le conversioni sono due:
-
dal manoscritto originale (referato) dell’autore al markdown:
gli articoli in DOCX oppure ODT andrebbero salvati nella cartella appropriata (./0-original/) per esser convertiti; saranno rinominati con nomi dei file più sicuri e semplici (se il manoscritto deriva dal flusso di lavoro di OJS, verrà utilizzato l’ID della proposta) e convertiti in markdown, con una sezione per i metadati predefinita; i nuovi file convertiti saranno copiati nella cartella di impaginazione (./1-layout/) dove gli editor potranno iniziare i lavori di formattazione e sui metadati; -
dal markdown ai formati per la pubblicazione (formati della gabbia):
in questo passaggio i file per l’impaginazione vengono convertiti nei vari formati di pubblicazione (e appariranno in./2-publication/). Questo passaggio è pensato per essere ripetuto fino a che gli articoli risultanti siano pronti per la pubblicazione.
Ciascuna conversione è scriptata per essere applicata a tutti gli articoli presenti nelle cartelle di origine, e include la generazione di copie di archivio.
Altri due script servono per una elaborazione elementare delle immagini (le immagini sono ridotte, se necessario, e vengono generate delle versioni a bassa risoluzione per gli HTML) e per l’archiviazione finale della cartella di lavoro, alla pubblicazione del fascicolo. L’ultimo script genera inoltre una versione “autosufficiente” (self-contained) dei manoscritti in markdown, nella quale sono state incorporati i metadati e le impostazioni a livello di fascicolo e di rivista.
Formati di pubblicazione
HTML è il formato nativo del World Wide Web e come tale dovrebbe essere l’opzione principale anche per la comunicazione accademica. L’HTML è un formato che offre alcuni vantaggi importanti per gli articoli scientifici:
- una leggibilità più facile, indipendentemente dal dispositivo in uso;
- annotazione semantica avanzata;
- è un buon formato per la preservazione in digitale (i file inoltre sono self-contained, le immagini sono incorporate nel file in base64).
La semantica è stata aggiunta prendendo esempio da precedenti (e più avanzate) esperienze di HTML scientifico, come scholarly HTML e RASH. Gli articoli in HTML sono annotati in Schema.org, partendo dalla proprietà ScholarlyArticle, usando RDFa Lite. Purtroppo al momento non c’è alcuna annotazione nel corpo dell’articolo, ed RDFa Lite è applicato solo ai metadati del paper.
Il PDF viene generato da pandoc tramite XeLaTeX, pertanto è disponibile il supporto a UTF-8 e l’uso di font personalizzati per ciascuna rivista, oltre all’eccellente composizione tipografica di LaTeX. Il modello utilizza hyperref per avere collegamenti alle citazioni, e consente di impiegare fino a tre differenti caratteri per il corpo del testo, titoli e intestazioni, e paratesto.
JATS XML e TEI XML sono due formati critici se si vuole essere interoperabili con altre piattaforme; è possibile generare articoli in questi due formati, tuttavia i modelli richiedono ulteriori controlli.
Fascicoli pubblicati
Ad oggi tre riviste hanno pubblicato un fascicolo con questo flusso di lavoro, mentre altre tre riviste dovrebbero aggiungersi al primo gruppo di pionieri:
- Cinergie, No 12 (2017): la prima redazione ad avermi aiutato a testare questo flusso; il fascicolo è composto da 28 elementi (1 editoriale, 23 articoli e 4 recensioni), tutte pubblicate in HTML e PDF; 11 contributi contengono immagini, tuttavia all’epoca non era ancora stata introdotta la possibilità di impiegare due differenti versioni dei file per PDF ed HTML. I PDF sono stati composti con i font Libre Caslon Text e Lato (per titoli e paratesto).5
- ZoneModa Journal, Vol 7 (2017): il fascicolo consiste di 18 elementi (2 editoriali, 8 articoli e 8 altri contributi non referati), oltre a un “intermezzo” impaginato separatamente; 5 contributi contengono immagini, in due formati differenti per i PDF (con una risoluzione fino a 300DPI) e HTML (a bassa risoluzione). Le sezioni degli articoli non sono numerate. I PDF sono composti in EB Garamond, un font personalizzato per i titoli e Ubuntu font per il paratesto.5
- USAbroad, Vol 1 (2018): un fascicolo (ancora aperto) che contiene un editoriale e 5 articoli, con testo indentato; questo è stato inoltre il primo fascicolo ad esser stato interamente sottoposto all’intero flusso di gestione delle proposte di OJS. I PDF sono composti in Libre Baskerville e Libre Franklin (per titoli e paratesto).5
Tutti i fascicoli includono inoltre una versione JATS XML degli articoli (non pubblicata).
A proposito: tutte e tre le riviste adottano anche la mia grafica standard per riviste su OJS 2.4. Il foglio di stile HTML è basato su questa grafica, include regole minime incorporate nell’HTML (indice, margini, regole di indentazione), mentre la maggior parte dello stile deriva dal foglio di stile della rivista. Alcuni elementi dell’articolo, come ad esempio abstract e biografie degli autori, sono nascosti se l’articolo viene visualizzato all’interno di OJS, dato che sono informazioni ridondanti in quel contesto.
Limitazioni e problemi noti
Al momento questa soluzione è ancora rudimentale e richiede una buona dose di (ottuso) copia&incolla per importare i metadati da OJS, e questa cosa dovrebbe poter essere automatizzata; inoltre questa soluzione non sfrutta tutte le potenzialità di pandoc. Ulteriori migliorie potrebbero derivare dall’uso di filtri, per esempio per avere collegamenti ai riferimenti per immagini e tabelle, e per avere una maggiore flessibilità riguardo ai metadati.
Tempo permettendo, vorrei anche esplorare la possibilità di preparare un file unico per ciascun fascicolo, con indice e colophon, in PDF ed ePub.
Questo flusso di lavoro è stato realizzato nonostante il poco tempo dedicato e nonostante le mie esperienze molto limitate, sia nella realizzazione di script, sia in LaTeX, annotazioni semantiche etc. Per questi motivi apprezzerò un sacco ogni parere, suggerimenti e aiuti.
-
anche se siamo decisamente lontani dall’idea espressa da Tim Berners-Lee & James Hendler in questo breve corsivo (ad accesso limitato!):
«Publishing on the semantic web», Nature 410, 1023–1024 (26 April 2001) https://doi.org/10.1038/35074206. ↩︎ -
Scholarly HTML, Scholarly Markdown, Academic Markdown: vari progetti, nati e rilanciati varie volte, tutti con lo stesso obiettivo, scrivere articoli scientifici in maniera più intelligente. ↩︎
-
“semplice” va qui intesto come il contrario di “complesso”, non come sinonimo di “povero”. ↩︎
-
Vorrei tanto provare a convertire i testi anche da altri formati, come ad esempio LaTeX. ↩︎
-
Questi bei font meritano una menzione speciale: Libre Caslon Text, Libre Baskerville e Libre Franklin sono di Pablo Impallari (et. al.); EB Garamond è uno stupendo Garamond di Georg Mayr-Duffner, è inoltre molto completo e supporta bene gli alfabeti greco e cirillico. ↩︎ ↩︎ ↩︎
comments powered by Disqus