Pandoc, un convertitore universale di testi
22 Aug 2017Ci sono strumenti che hanno cambiato il mio modo di lavorare e pandoc ha portato sicuramente cambiamenti grandi e – spero – profondi.
Mi ha permesso infatti di sfruttare a pieno il Markdown e i suoi vantaggi, potendo quindi lavorare su semplici file di testo; la transizione dai programmi di videoscrittura (!) come MS Word e Open Office/LibreOffice Write ai file di testo semplice in Markdown e YAML, gestiti da un editor come Atom, si è completata proprio perché con pandoc posso poi convertire il testo in altri formati (e soprattutto in PDF) velocemente e con una buona qualità.
Conto di scrivere e pubblicare a breve qualcosa su come sto usando pandoc a lavoro, intanto come antipasto vi racconto alcune sue potenzialità.
Cos’è pandoc
Pandoc è un software creato nel 20061 da John MacFarlane, professore di filosofia a Berkeley. Si definisce un «coltellino svizzero» a disposizione per chi avesse l’esigenza di convertire dei testi da un formato all’altro e in effetti è in grado di leggere e scrivere una moltitudine di formati.
{kind=link}
Grazie a pandoc è ad esempio possibile convertire un testo in HTML alla sintassi MediaWiki, quella utilizzata su Wikipedia. Oppure prendere un testo da Wikipedia, copiando il testo marcato in MediaWiki, per poi convertirlo in un file docx con link, corsivi e soprattutto intestazioni di sezione funzionanti e formattate correttamente.
Pandoc e Markdown
Il meglio di sé lo da comunque lavorando avendo come formato di riferimento il Markdown, che pandoc è in grado di interpretare nelle sue molteplici varianti. Ad esempio ottengo ottimi risultati lavorando su appunti in Markdown: è possibile tramite pandoc convertirli in formato docx o PDF; oppure dividerli in sezioni e poi convertirli in slide HTML da usare tramite reveal.js o altri sistemi analoghi (Beamer, ad esempio).
La conversione è semplice e veloce, basta lavorare da terminale usando:
pandoc filedaconvertire.md -o fileconvertito.pdf
dove filedaconvertire è l’input e fileconvertito l’output. In questo modo si otterrà un PDF dal file in Markdown (che può avere come estensione anche .txt).
Opzioni e personalizzazioni
Il vantaggio principale di lavorare da terminale è la ripetibilità: si possono effettuare molteplici operazioni su più file, o anche integrare pandoc in un flusso di lavoro più complesso (lo vedremo…).
Se il comando di base è elementare, è però possibile specificare molteplici opzioni come ad esempio:
pandoc filedaconvertire.md -N --write=html5 -s -o fileconvertito.html
che convertirà in HTML il nostro testo in Markdown, ma in più specifica che non avremo una porzione di HTML ma un file standalone e quindi comprensivo dell’head (-s), in formato HTML5 (--write=html5) e, chicca non indifferente, avrà le sezioni numerate automaticamente (-N).
Pandoc infatti interpretando il testo è in grado di applicare numerose varianti, quali appunto la numerazione delle sezioni o la generazione di un indice automatico (con --toc, utile in HTML e PDF). Una panoramica piuttosto esaustiva delle possibilità di pandoc è disponibile sul suo manuale online.
La complessità possibile è piuttosto elevata, tant’è che possiamo generare un ebook in formato ePub partendo sempre da Markdown:2
pandoc filedaconvertire.md metadati.yaml --template=modello-personalizzato.epub2 -s -o fileconvertito.epub
questo comando genererà un ebook a partire dal file in Markdown e usando i metadati aggiuntivi che abbiamo voluto indicare tramite il formato YAML. In aggiunta abbiamo specificato un diverso modello per la generazione dell’ebook, a cui possiamo aver aggiunto una serie di personalizzazioni rispetto al template standard, magari sfruttando anche i metadati dello YAML.
Template e metadati
I template personalizzati possono essere realizzati partendo da quelli standard, ottenibili con il seguente comando (modificando l’estensione a seconda del tipo di formato in cui vogliamo convertire il testo):3
pandoc --print-default-template=html5 >> default.html5
All’interno del file che viene generato da questo comando, troveremo una pagina HTML contenente una serie di variabili che pandoc utilizza nello scrivere l’output. Guardiamo ad esempio questa porzione di codice, per chi sa l’HTML:
$if(title)$
<header>
<h1 class="title">$title$</h1>
$if(subtitle)$
<p class="subtitle">$subtitle$</p>
$endif$
$for(author)$
<p class="author">$author$</p>
$endfor$
$if(date)$
<p class="date">$date$</p>
$endif$
</header>
$endif$
$if(toc)$
<nav id="$idprefix$TOC">
$toc$
</nav>
$endif$
$body$
Tutto il codice delimitato dal simbolo del dollaro viene interpretato da pandoc, pertanto se è specificato un titolo ($if(title)$ … $endif$) verrà visualizzato l’header con il titolo in <h1>; così se oltre al title sono specificati uno o più author per ciascuno di essi verrà stampato il contenuto di author all’interno di un apposito paragrafo ($for(author)$ … $endfor$).
In fase di personalizzazione è possibile aggiungere nuovi parametri che, se presenti, pandoc utilizzerà per ottenere il risultato desiderato. Ci sono vari modi per specificare title, author, date etc, ma per lavori complessi la soluzione migliore credo sia sempre l’utilizzo di blocchi di YAML, che possono essere forniti come file distinti o incorporati nel file Markdown, all’inizio.
Ad esempio se utilizziamo l’esempio del post precedente come metadati integrati nel file di origine (ma possono anche essere forniti separatamente):
---
title: "Il titolo del mio testo"
description: |
Una descrizione del mio testo, non tanto breve, al punto che
la faccio apparire su più righe in questo modo
tags: [ "varie", "tag", "descrivono", "il mio testo" ]
# questa riga inizia per cancelletto, quindi è un semplice commento
date: "2017-08-21"
# questo testo ha più autori, elenchiamoli
author:
- Niccolò Copernico
- Galileo Galilei
---
Lorem Ipsum, qui inizia il mio testo in Markdown.
possiamo personalizzare il template in HTML in modo che preveda anche la description, aggiungendo quindi il riferimento appropriato (qui uno stralcio):
$if(date)$
<p class="date">$date$</p>
$endif$
$if(description)$
<div class="description">$description$</div>
$endif$
</header>
$endif$
Filtri
Sono possibili personalizzazioni ancora più spinte con l’uso dei filtri (che possono agire sia in fase di lettura dell’input, sia in fase di scrittura dell’output). Questi sono scrivibili in vari linguaggi (Hashkell, python, lua…) e un esempio di filtro è pandoc-citeproc, che consente di gestire i riferimenti bibliografici di uno o più testi in maniera automatica.4
Non entro ulteriormente nell’argomento filtri perché non ho ancora messo il naso in questo che sarebbe un passo decisamente avanzato per le mie capacità.
PDF e LaTeX
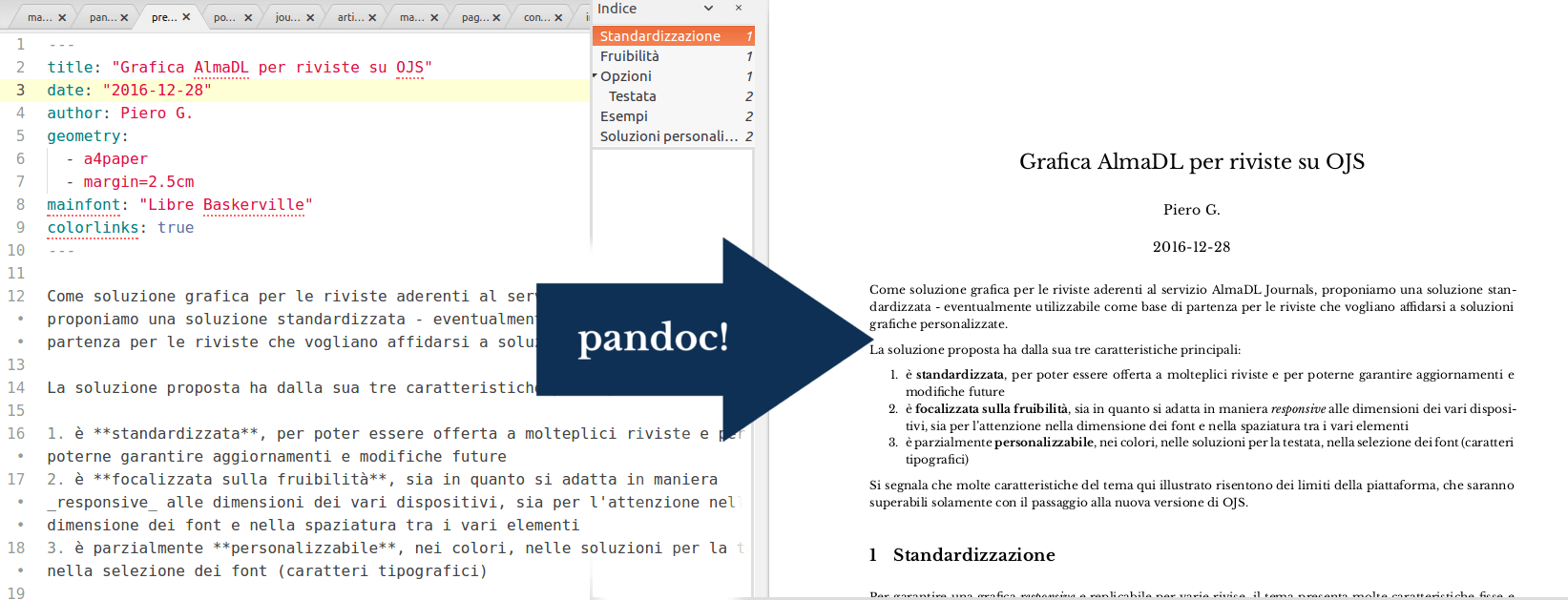
Anche dei semplici appunti possono diventare un serissimo PDF, e in fretta
Una grande caratteristica di pandoc è che consente di convertire anche da e in LaTeX e che lo usa per le conversioni in PDF, di conseguenza eredita tutta la completezza e accuratezza possibile con LaTeX. Personalmente ne sono rimasto entusiasta, da neofita, considerando che non ho mai ottenuto tanta qualità da un PDF generato in altri modi. Ma serve un passo indietro.5
Ho già accennato al linguaggio di composizione tipografica TeX poiché Allin Cottrell nel 1999 ne raccomandava l’adozione come soluzione qualitativamente elevata per produrre testi.6 Oggi possiamo dire tranquillamente che l’uso di TeX per prendere semplici appunti sia un notevole overkill, e in più grazie a pandoc è possibile ottenere un po’ della qualità di LaTeX (che semplificando molto è una evoluzione di TeX) nella preparazione dei PDF senza doverlo conoscere: se ci accontentiamo delle impostazioni predefinite, ovvio!
Per personalizzare la generazione dei PDF è necessario comunque affrontare anche LaTeX e il suo template di default in pandoc. È molto completo e prevede già varie opzioni, qui un consiglio per cominciare a personalizzare i PDF senza troppe difficoltà:
usare come motore per la compilazione XeLaTeX, che consente di utilizzare i caratteri tipografici (font) di sistema, tramite il seguente comando:
pandoc filedaconvertire.md --latex-engine=xelatex -o fileconvertito.pdf
e quindi specificare i caratteri e una serie di variabili già previste, tramite lo YAML:
# con geometry definiamo la dimensione della pagina e i margini
geometry:
- a4paper
- margin=1.25in
# potete specificare il font da utilizzare, se installato nel vostro computer (eg: Times New Roman e Arial)
mainfont: "Libre Baskerville"
# per colorare i link, altrimenti neri
colorlinks: true
Chi volesse potrebbe poi procedere di slancio e personalizzare direttamente il template, inserendo variabili e richiamando classi e pacchetti per gestire stili, paginazione personalizzata, intestazioni e piè pagina o altro; ma una minima conoscenza di LaTeX è indispensabile – anche perché vorrete probabilmente compilare non solo in PDF ma anche in LaTeX, e usare poi un editor TeX per controllare eventuali errori.
Aldilà dell’aggiustamento di uno o più template, operazioni che dovrebbero avvenire raramente, il vantaggio fondamentale è che – così come per l’HTML o altro – con pandoc possiamo sfruttare la qualità di LaTeX evitandone la sintassi, ma sfruttando quella molto più agile del Markdown.
-
continua la saga di progetti il cui uso è magari innovativo quando si parla di biblioteche o di editoria, ma sicuramente non così nuovi, come già visto nel primo post di questo sito ↩︎
-
disclaimer: non ho mai provato a generare un ePub tramite pandoc, come tutto credo che per avere un processo ripetibile e di qualità serva fare varie prove e aggiustamenti; pandoc non fa miracoli (quasi…) e quindi non sarà tutto sempre perfetto ↩︎
-
sono presenti anche su GitHub ma consiglio di generarli con Pandoc per evitare discrepanze a causa di aggiornamenti ↩︎
-
altro argomento che non ho ancora guardato con la dovuta attenzione, rimando a questi esempi ↩︎
-
con un disclaimer: a LaTeX mi sono approcciato solo recentemente e in maniera molto disorganica ↩︎
-
Cottrell, Allin. «Word Processors: Stupid and Inefficient», 29 giugno 1999. http://ricardo.ecn.wfu.edu/~cottrell/wp.html; l’ho citato nel post precedente su Markdown e YAML ↩︎
comments powered by Disqus